首先向大家通告一个好消息,stable diffusion webui 已经支持中文本地化了,这进一步降低国内玩家的门槛,大家快去Github更新项目吧
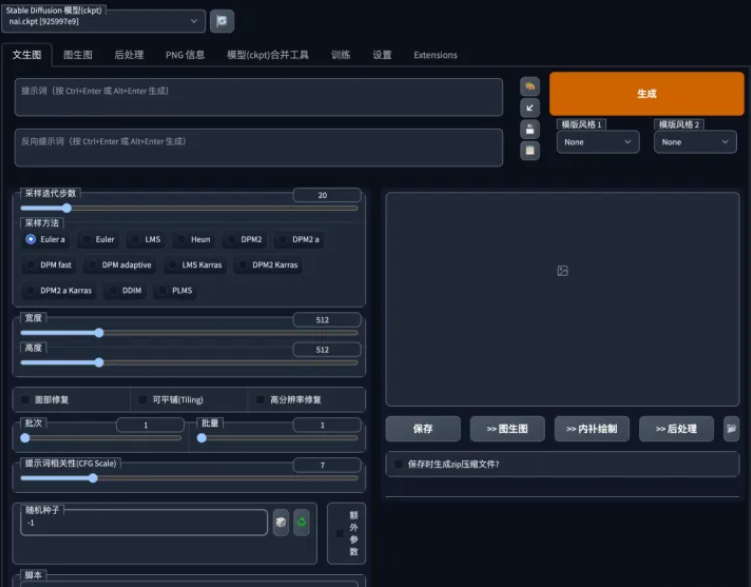
AI模型通过神经网络训练得到许多的特征元素,AI绘画时会根据各种特征元素的加权计算元素出现的概率。例如:蓝色的眼睛、金色卷发、微笑的嘴巴...。
Prompt 正向提示符,通过关键词对特征元素提供正向加权。它可以是详细的提示符,也可以是大致的提示符,所提供的提示符越详细生成的结果就越贴合需求。AI能应用的元素必须是训练学习过的,如果训练集中没有佩奇,它就无法绘制佩奇的相关元素。
Negative Prompt 反向提示符,提供反向加权,降低特征元素出现的概率。
CFG Scale 图像与提示符的一致程度。Denoising strength 标识采样图的保留程度,值越小加的噪声越少,对采样图保留越多。
Seed随机数种子。种子一致,参数一致,生成的图像就会比较相同。
Sampling Steps 采样步长。步长越小随机性越高,步长越大拒绝采样结果的概率越高,步长越大效率越低。个人推荐采样步长设置在30左右
Sampling Method采样方法,通过求解函数f(x)得到分布p(x)的期望值。Stable Diffusion提供了多种采样方法以适配众多特定的应用场景。没有绝对完美的采样方法,在使用时候可以多测试一下几种采样方法,只要输出结果合适就可以了。
Batch count 和 Batch size 决定生成多少张图像,前者越大消耗的时间越长,后者越大需要的显存越大。
三种图像优化技术
- Restore face:面部优化技术
- Tiling:CUDA矩阵乘法优化
- Highres:使用两个步骤的过程进行生成。第一步以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数 Scale latent 对图像进行缩放。第二步是升级从上一步产生完整的图像,Denoising strength 决定算法对图像内容的保留程度,在0处,什么都不会改变,而在1处,则引用图像