novel ai作为一款人工智能生成软件,不管是根据描述生成文章还是根据描述生成图片,其人工智能的核心要点都包含两个部分:蓝色的用于理解描述的自然语言处理器和红色的用于生成结果的生成器。

对输入表述的解析,就是处于自然语言解析阶段。在这一阶段,它将文本信息转换为数字表示,从而捕捉文本中的想法。对于不同的文本,其转换为的数字量也有区别,这就是显示在我们输入框右下角的输入量。
在训练embedding的时候,我们也被要求选择embedding词所代表的向量数,这个向量数,就是我们要训练的词会被解析成的数字量。之后我们统一使用输入量来称呼这个数量。
被蓝色的自然语言处理器解析后的输入表述会通过CLIP网络结合图像,以数组的形式保存下来,即下图中蓝色方格的token embedding。

CLIP网络就是理解tags如何被写入模型的关键点。下图就是CLIP网络在训练过程中是如何将tags与图像进行结合的。
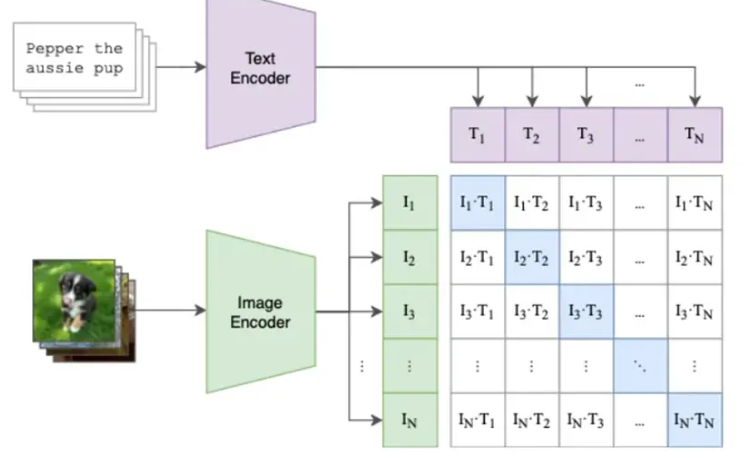
输入描述和图片在分别经过两个神经网络(Encoder)变成了计算机更容易理解的数字编码后,进行了一个对比训练,从而将描述词和图片一一对应上。这个过程中就训练这两个Encoder。这两encoder就会在之后的txt2img或者img2img中发挥作用。
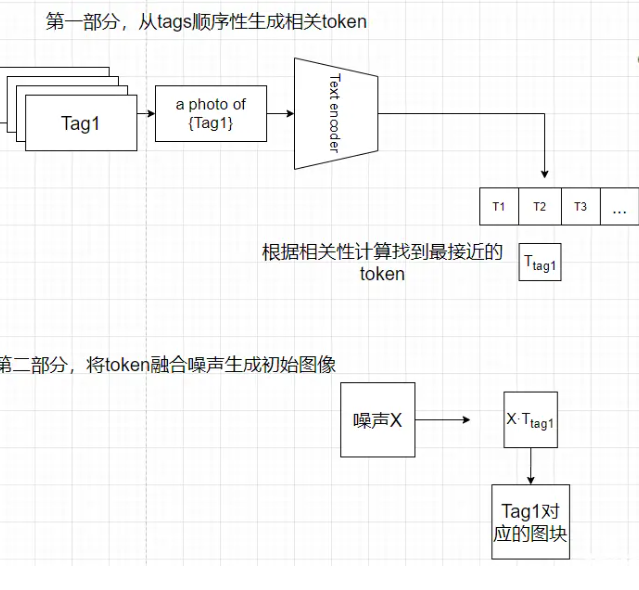
即可以得到总结
1.输入的词句,会被蓝色的自然语言处理器解析成一个个数字,存进蓝色的数组中
2.这个输入的数组会按顺序结合高斯噪声输入到红色的生成器中,生成粗糙的图像
3.将粗糙的图与输入的数组重复第二步,对生成的图像镜像迭代
4.将迭代完的输入黄色的放大器,扩大图像分辨率,是图像细致。